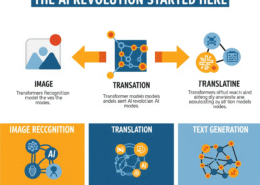
What Is a Transformer?
A Transformer is a neural network architecture introduced in the landmark 2017 paper “Attention Is All You Need” by Vaswani et al. It sparked a revolution in sequence-to-sequence (seq2seq) modeling by eliminating recurrence and convolution, relying instead on a powerful attention mechanism.
Unlike Recurrent Neural Networks (RNNs), which process sequences token by token, Transformers process entire sequences in parallel, enabling massive speed improvements and superior handling of long-range dependencies. This innovation laid the groundwork for the rapid evolution of modern artificial intelligence.
Core Architecture & Functioning
1. Encoder–Decoder Stack
- Encoder: Composed of N identical layers, each containing:
- Multi-head self-attention
- Position-wise feed-forward network
- Decoder: Also N layers, includes:
- Masked self-attention (to maintain autoregressive behavior)
- Encoder–decoder attention
- Feed-forward and normalization layers
2. Positional Encoding
Transformers lack recurrence, so sinusoidal positional encodings are added to token embeddings to capture order and sequence relationships, enabling positional awareness.
3. Scaled Dot-Product Self-Attention
Each token is represented by:
- Query (Q)
- Key (K)
- Value (V)
Self-attention is computed as:
Attention(Q, K, V) = softmax(Q·Kᵀ / √dₖ) · V
This allows every token to attend to all other tokens, dynamically weighting their importance.
4. Multi-Head Attention
Instead of a single attention mechanism, Transformers use multiple parallel “heads”, each learning different representations. These are concatenated and linearly projected, allowing the model to grasp complex relationships across tokens.
5. Feed‑Forward & Layer Normalization
Each layer includes:
- A position-wise feed-forward network
- Residual connections
- Layer normalization for stability and convergence
How Transformers Improved Seq2Seq
| Limitation of RNN/CNN Models | Transformer Advantage |
|---|---|
| Sequential processing only | Full parallelism in training |
| Limited context window | Global token-to-token attention |
| Slow inference in generation | Masked self-attention enables faster decoding |
These improvements enabled Transformers to dominate tasks like machine translation, summarization, and more, outperforming prior models in both efficiency and accuracy.
“Attention Is All You Need” – The Groundbreaking Paper
Key contributions from Vaswani et al.:
- Introduction of scaled dot-product attention
- Design of a fully attention-based encoder–decoder structure
- Development of multi-head attention
- State-of-the-art results in English–German and English–French translation benchmarks
The paper established attention as the core computational primitive of modern deep learning.
Applications & Impact
Transformers are no longer confined to natural language processing. They are now the foundation of AI across domains:
- Language Models: GPT, BERT, T5, RoBERTa — used for generation, classification, QA, summarization
- Machine Translation: Still the top-performing model in multilingual settings
- Vision: Vision Transformers (ViT), DETR, and image captioning systems
- Audio: Speech recognition and synthesis with models like Whisper and Wav2Vec
- Multimodal Models: CLIP, Flamingo, Gemini — handling text, images, audio together
- Reinforcement Learning & Robotics: Decision Transformers learning from past trajectories
Transformers have become AI’s Swiss Army Knife — versatile, scalable, and transferable across tasks.
Why Transformers Matter
Training Speed & Scalability
- Enables parallel computation across GPUs/TPUs
- Supports scaling to billions of parameters (e.g., GPT-4, Gemini, Claude)
Deep Contextual Understanding
- Captures relationships across long texts or sequences
- Avoids information loss seen in earlier models
Transfer Learning & Fine-Tuning
- Pretrained Transformers can be fine-tuned on downstream tasks with minimal data
- Foundation models enable rapid adaptation to new applications
Democratizing AI Access
- Open-source models like BERT and T5 have empowered researchers, developers, and students worldwide
- Hugging Face’s Transformers library made cutting-edge models accessible with just a few lines of code
Future Potential
- Transformers are converging with other modalities — e.g., video transformers, biological sequence modeling, protein folding, drug discovery, and more
- The architecture is flexible enough to power the next generation of AGI-ready models
The Transformer architecture, unleashed by “Attention Is All You Need”, redefined how machines process information. Its attention-first design replaced older paradigms with a more scalable, accurate, and versatile foundation. Whether it’s generating text, understanding images, or controlling robots, Transformers sit at the heart of today’s AI revolution.
Why do Transformers matter?
Because they didn’t just improve AI — they transformed it.